The VODAN Platform & the CEDAR Workbench: Semantic Technology to Ensure FAIR Patient Data in Africa
LUMC and Leiden Global were represented at the 2023 Conference of the American Medical Informatics Association which opened on 12 November. Prof. Mirjam van Reisen, Prof FAIR Data Science, and Erik Schultes, presented at the scientific panel on “The CEDAR Workbench: Semantic Technology to Ensure FAIR Data” alongside Mark A. Musen, M.D. from the Center for Biomedical Informatics Research, Stanford University School of Medicine, Stanford; Anthony L. Juehne, from the Office of the Director, National Institutes of Health, Bethesda; and Rachel L. Richesson, University of Michigan Medical School, Ann Arbor.
The presentations focused on the LUMC research on the curation of medical data to ensure data is Findable, Accessible (under well-defined conditions), Interoperable and Reusable (FAIR), and Federated AI Ready.
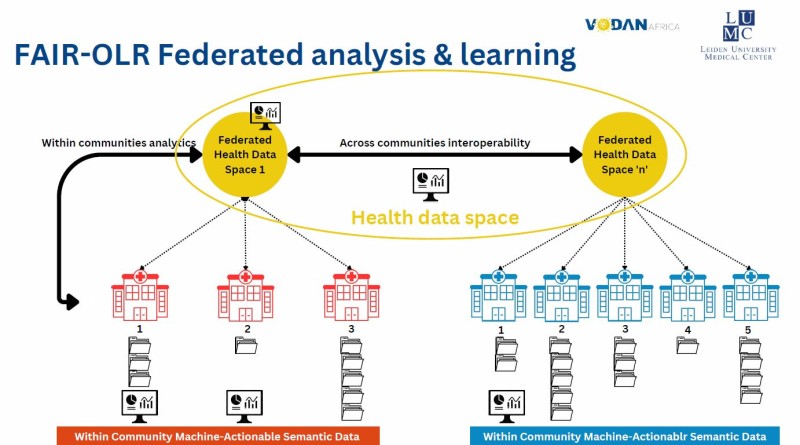
The Research programme of VODAN of which Prof. Van Reisen is the PI has tested the potential of knowledge integration with data held in residence, within the health facility. The data is annotated with semantic attributions and is machine-actionable, produced in computer-readable language. The project has been deployed in 90 health facilities across 8 African countries, demonstrating the potential of secure, ethical patient data curation, in which the data does not leave the health facility or the country. The data is stored securely and can be visited for improvement of quality of care within the health facility. The data can also be visited for surveillance purposes across the health facilities, located in different geographies and residing under distinct regulatory frameworks which are respected alongside GDPR as the base standards for personal data protection.
The federated data that VODAN helps produce belongs to the health data space, in which the data can be re-used and used for interoperable purposes if permission is provided by the data producer and/or data subject. This provides a sustainable architecture in which the costs of data production and curation can be covered by the value generated from the reuse of new insights by other customers (under stringent permission controls). The architecture represents a granular source from patient health records, as a basis of a learning health care system.
Dr. Schultes presented how sets of research findings and data can be retrieved by indexing according to FAIR principles, which supports the work of research funders, such as ZonMw and NWO in The Netherlands. Representing the Go-FAIR Foundation, he presented the power of training of data stewards in establishing FAIR communities, to assist data integration across domains. The Metadata-for-Machines training has helped create training of trainers that support the introduction of FAIR-data principles in new communities. The collaboration with Stanford University Cedar for data annotation has been helpful in utilizing the services required.
A discussion on the importance of metadata and the production of data as FAIR at the source, produced in machine-actionable form is critical for further knowledge integration. The FAIR home with its roots in LUMC and Leiden Global made an inspiring presence with use cases being proudly presented and discussed in the academic seminar on the opening day of AMIA.

")










")





